


Résumé
De nombreuses disciplines scientifiques s'appuient sur des méthodes de calcul pour l'analyse des données, la génération de modèles et la prévision. La mise en œuvre de ces méthodes est souvent réalisée par des chercheurs ayant une expertise dans le domaine mais sans formation formelle en génie logiciel ou en informatique. Cet arrangement a conduit à une sous-appréciation de la durabilité et de la maintenabilité des outils logiciels scientifiques développés dans les environnements universitaires. Certains outils logiciels ont évité ce sort, notamment la bibliothèque scientifique Rosetta. Nous utilisons ce logiciel et sa communauté comme étude de cas pour montrer comment le développement de logiciels modernes peut être accompli avec succès, quel que soit le domaine. Rosetta est l'une des plus grandes suites logicielles pour la modélisation macromoléculaire.
Depuis le milieu des années 1990, le logiciel a été développé en collaboration par les RosettaCommons, une communauté d'universitaires de plus de 60 institutions à travers le monde avec des antécédents divers, y compris la chimie, la biologie, la physiologie, la physique, l'ingénierie, les mathématiques et l'informatique. Le développement de cette suite logicielle nous a fourni plus de deux décennies d'expérience sur la façon de développer efficacement des logiciels scientifiques avancés dans une communauté mondiale avec des centaines de contributeurs.
Introduction
Relever les grands défis dans diverses disciplines scientifiques nécessite des idées et des perspectives de la part des membres de l'équipe couvrant un large éventail d'expertises, avec une concentration soutenue qui persiste sur une période suffisamment longue pour atteindre des objectifs scientifiques audacieux.
Mais comment assembler une équipe qui peut réussir à travailler ensemble sur un objectif commun sur de longues périodes ?
Un récent rapport des académies nationales a résumé les principaux défis de la «science d'équipe» comme la diversité des membres, l'intégration interdisciplinaire des connaissances, la grande taille, l'alignement des objectifs, la dispersion géographique et l'interdépendance des tâches.
Nous partageons ici comment notre équipe a relevé ces défis. Notre expérience collective au sein du consortium RosettaCommons a été marquée par une extraordinaire collaboration au sein d'une équipe composée de petits groupes qui innovent chacun sur leurs propres projets. Ce travail d'équipe est possible car notre travail s'articule autour d'une suite logicielle partagée. L'émergence d'outils logiciels scientifiques partagés et distribués dans de nombreuses disciplines scientifiques offre la possibilité de former des communautés de recherche ciblées et productives.
Les compétences informatiques sont de plus en plus vitales dans un large éventail de disciplines scientifiques. Cependant, peu de programmes de formation dans ces domaines incluent l'enseignement de l'informatique ou du génie logiciel. Ainsi, de nombreux scientifiques mettent en œuvre leurs flux de travail dans des scripts ou des programmes transitoires axés uniquement sur la réponse à une préoccupation immédiate. Ces programmes manquent souvent de généralité, d'extensibilité, de commentaires de code ou de documentation, et peuvent être difficiles à intégrer avec d'autres méthodes.
En revanche, accomplir des tâches complexes et repousser les frontières scientifiques nécessite généralement la réutilisation d'algorithmes sophistiqués et validés. Un code partagé généralisé de manière appropriée peut permettre de construire de nouvelles méthodes complexes à partir de modules plus simples et réutilisables qui combinent des idées provenant de plusieurs sources. Nous avons utilisé un tel modèle pour développer la suite logicielle de modélisation macromoléculaire Rosetta.
Le succès et la longévité du projet ont reposé sur la culture d'une communauté autour de la base de code dans le but plus large de résoudre des problèmes scientifiques complexes en partageant des idées et des outils et en collaborant étroitement.
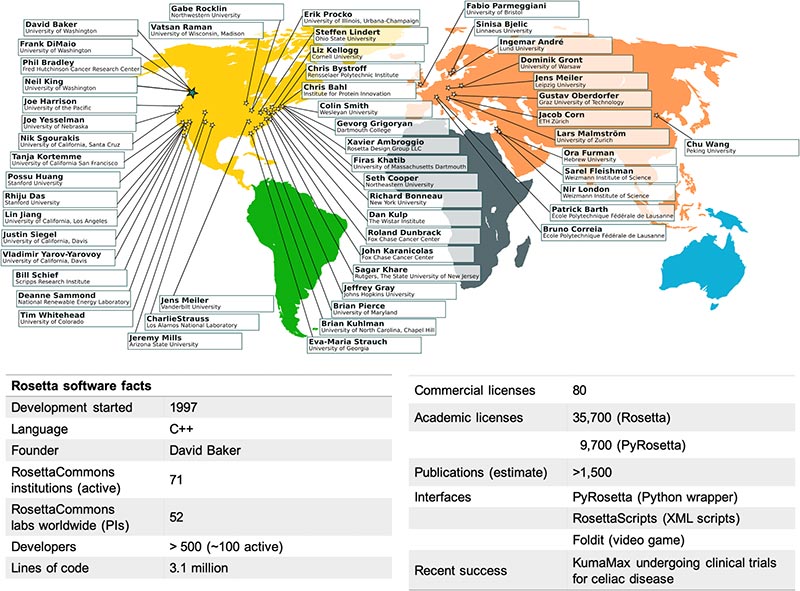
Figure 1 : Faits RosettaCommons.
Principaux laboratoires et institutions de RosettaCommons et faits de base sur notre logiciel en 2019
En plus de résoudre les problèmes techniques liés aux progrès scientifiques, notre communauté a établi des normes de codage, de publication et d'interaction avec la communauté qui ont permis une croissance et une santé continues du logiciel et de notre communauté pendant de nombreuses années. Nous nous réunissons au moins deux fois par an pour discuter des changements majeurs apportés à la base de code et pour partager nos nouveaux outils et les progrès scientifiques réalisés avec eux. De plus, nous formons de nouvelles collaborations lors de ces réunions et reconnaissons les membres qui ont apporté des contributions importantes à la base de code et / ou à la communauté. Pour assurer une entrée rapide dans le développement, nous organisons des sessions de formation régulières pour les nouveaux arrivants à travers la communauté. Nous avons créé un code de conduite auquel nous exigeons que nos membres adhèrent, quelles que soient leurs institutions. Nous sommes étroitement liés à notre vaste base d'utilisateurs pour améliorer davantage notre logiciel et l'appliquer à des problèmes scientifiques du monde réel. Notre communauté a changé notre façon de travailler, notamment en conjonction avec des outils relativement récents qui permettent l'interaction sociale à différents niveaux (GitHub, Slack, vidéoconférences).
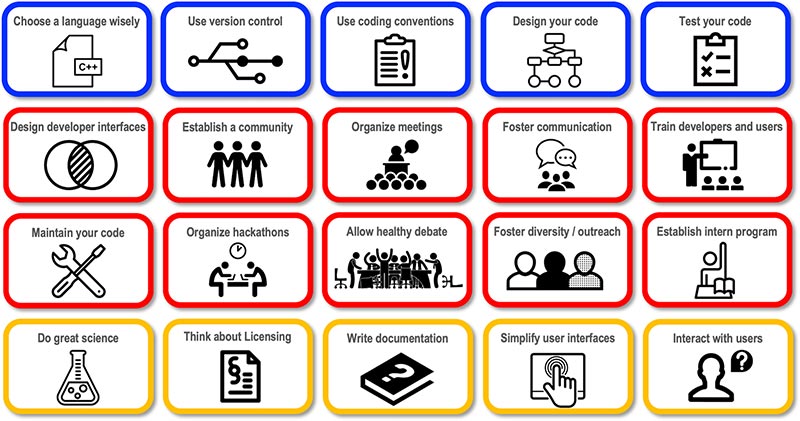
Figure 2. Piliers du succès dans le développement de logiciels scientifiques.
Les aspects techniques sont en bleu, les aspects sociaux en rouge et la diffusion et l'interaction utilisateur en jaune
Débuts et croissance de notre communauté
Le développement de notre suite logicielle a commencé au milieu des années 1990 dans le laboratoire de David Baker à l'Université de Washington. Rosetta a été initialement développé pour la prédiction de la structure des protéines et pour avoir un aperçu du repliement des protéines, ce qui reste un grand défi en biophysique théorique et sous-tend notre compréhension de la biologie, de la santé humaine et des maladies. Le projet a démarré lorsque deux étudiants diplômés ont mis en œuvre un algorithme d'échantillonnage Monte Carlo et une fonction de notation composée de termes basés sur la physique et basés sur les connaissances. Le protocole a réussi dans les défis de prédiction à l'aveugle, CASP 3 et 4. Suite à ce succès, plusieurs stagiaires post-doctoraux se sont joints au projet pour développer diverses applications de prévision et de conception de structures.
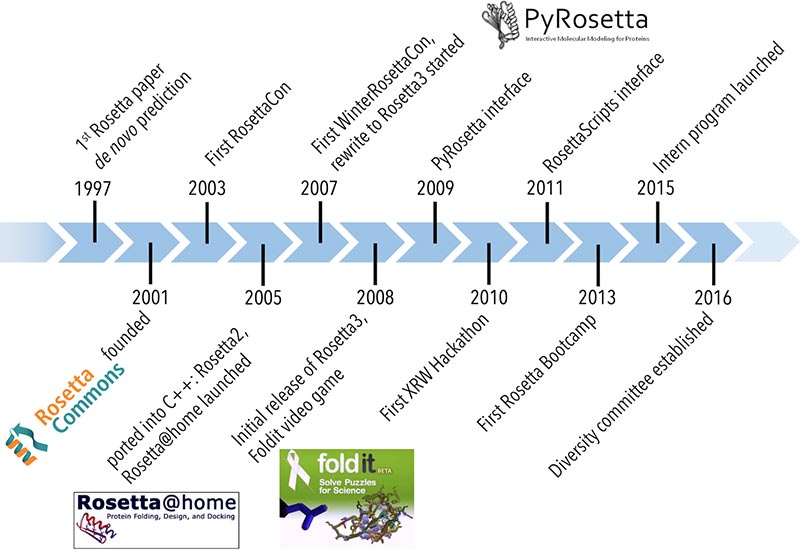
Figure 3. Histoire de Rosetta.
Jalons majeurs de l'histoire du développement de Rosetta.
Alors que les premiers développeurs ont commencé à occuper des postes indépendants dans diverses institutions, ils ont continué à développer et à améliorer leurs applications de modélisation, et il est devenu clair que l'amélioration de la collaboration entre les institutions serait bénéfique pour le progrès scientifique. Cela a conduit à la création de la communauté de développeurs RosettaCommons, qui impliquait un accord de propriété intellectuelle unique (licences). La structure RosettaCommons a permis une collaboration transparente entre de nombreuses institutions, ce qui a stimulé les développements dans de nombreuses directions différentes. En 2019, les RosettaCommons sont devenus des laboratoires dans 71 institutions à travers le monde, supervisant un projet comprenant plus de 3 millions de lignes de code avec la contribution de plus de 800 scientifiques. Le code a été autorisé à environ 35 700 chercheurs universitaires et 80 entités commerciales.
Aspects techniques
Historique linguistique de la base de code
La première base de code a été écrite en Fortran puis traduite automatiquement en C ++ (par Objexx Engineering), qui a été publiée à l'été 2005 sous le nom de Rosetta ++ (également connue sous le nom de Rosetta2). Au cours des deux années suivantes, la traduction automatique s'est avérée impossible à poursuivre pour le développement, et un ingénieur logiciel a été embauché pour implémenter le logiciel en tant que bibliothèque orientée objet, appelée librosetta. Bien que la première tentative de création d'une hiérarchie orientée objet se soit révélée lourde et rigide et ait finalement dû être abandonnée, elle nous a donné un aperçu de meilleurs choix pour nos objets centraux et leurs relations. La prochaine réécriture orientée objet de la base de code a été lancée à l'été 2007 par deux de nos développeurs principaux qui étaient à la fois des scientifiques et des ingénieurs logiciels (Andrew Leaver-Fay, membre du laboratoire Kuhlman, et Phil Bradley, au Fred Hutchinson Centre de recherche sur le cancer). Ce code s'appelait initialement miniRosetta et deviendrait plus tard Rosetta3, sorti début 2009. MiniRosetta a également corrigé une faille de conception de Rosetta ++ qui se présentait comme une seule application monolithique avec des options d'entrée qui permettaient d'invoquer de nombreux protocoles différents. En revanche, les protocoles de Rosetta3 sont généralement des applications autonomes avec leur propre nom. Il existe actuellement plus de 200 applications de ce type.
Deux interfaces de script sont également prises en charge: RosettaScripts, qui est une interface basée sur XML qui permet le développement de protocoles à partir de blocs de construction modulaires sans compilation supplémentaire, et PyRosetta, qui permet le développement de protocoles basés sur Python et une intégration facile avec outils tiers. Les différentes interfaces sont enracinées dans la base de code Rosetta3 de 2007, qui est toujours utilisée, développée et maintenue au moment de la rédaction de ce document, 12 ans plus tard. Dans notre cas, après plusieurs itérations, nous avons trouvé des abstractions reconfigurables et extensibles appropriées dans un cadre de programmation orienté objet dans le langage C ++ pour atteindre nos objectifs scientifiques.
Contrôle de version
Dans le développement de logiciels, le contrôle des versions est important à la fois pour documenter les modifications apportées au logiciel au fil du temps et pour garantir que des lignes de développement parallèles indépendantes peuvent être fusionnées en un seul logiciel unifié. Le contrôle de version est particulièrement important pour les grandes bases de code avec des dépendances complexes de fichiers et de hiérarchies de classes et où chaque révision de la ligne principale de développement doit être compilée et exécutée.
Au milieu des années 1990, nos développeurs ont stocké des versions de la base de code dans des sous-répertoires nommés de façon cryptée. Un référentiel de code source unique a été créé pour lequel une seule personne avait des autorisations d'écriture (Carol Rohl), en utilisant le système de version simultanée alors en vogue (CVS).
CVS a mal évolué à mesure que la communauté des développeurs se développait, et vers 2006, la communauté est passée au système de contrôle de version centralisé Subversion (SVN), qui a bien fonctionné pour nous pendant de nombreuses années. À mesure que le nombre et l'étendue géographique des développeurs augmentaient et que la complexité du code augmentait, notre serveur SVN unique est devenu submergé. Les développeurs éloignés du serveur central de Seattle ont rencontré des fusions douloureusement lentes ou impossibles en raison de délais d'attente, ou ont vu les modifications locales non enregistrées effacées.
En 2013, nous avons migré vers des référentiels privés sur GitHub, qui utilise le système de contrôle de version distribué Git. Dès le début, nous avons créé des conventions d'interaction avec GitHub. La nature décentralisée de Git a extrêmement bien servi la communauté en soutenant des milliers de différentes branches de développement du monde entier qui peuvent être relativement facilement fusionnées dans la branche principale de développement.
Depuis, nous avons institué des points de contrôle supplémentaires pour les fusions, y compris des tests automatisés et exigeant des révisions de code indépendantes d'autres développeurs de la communauté sur chaque ensemble de modifications. Les examens des demandes de tirage nous ont permis d'améliorer la qualité du code et de réduire les bogues. Le contrôle administratif du référentiel de code incombe aux développeurs seniors, plutôt qu'aux chercheurs principaux.
Cadre de test
Les tests de code sont nécessaires pour garantir que le logiciel fonctionne correctement et de manière stable dans différents environnements informatiques, fournit une sortie attendue et reproductible, s'exécute dans un certain délai et atteint un certain objectif technique.
À partir de 2004, nous avons créé notre propre infrastructure de test car les progiciels standard à l'époque ne fournissaient pas les fonctionnalités dont nous avions besoin. Les tests sont devenus une partie intégrante de notre développement logiciel. Parce que l'exécution de tests localement sur diverses architectures et modes de construction est difficile et prend du temps pour les individus, notre cadre comprend un serveur de test dédié sur lequel les tâches sont réparties et les résultats sont collectés.
RosettaCommons utilise les revenus de licences pour acquérir et maintenir le matériel sur lequel ces tests sont exécutés.
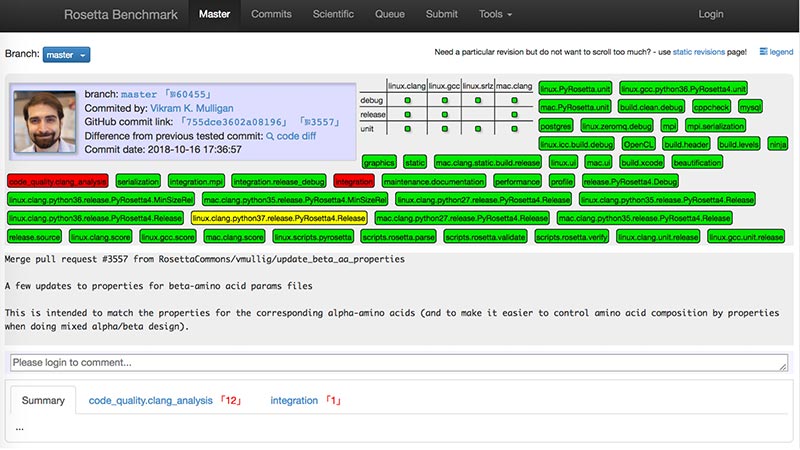
Figure 4. Test du logiciel.
Les tests sont essentiels pour garantir la stabilité et l'exactitude des logiciels. Il s'agit d'une vue de notre tableau de bord de serveur de test pour une fusion spécifique dans la branche principale de Rosetta. Nous exécutons en continu un grand nombre de tests, tels que des tests de construction, des tests unitaires, des tests d'intégration, des tests de performances, des tests d'analyse de code et des références scientifiques. Les balises vertes, rouges et jaunes indiquent la réussite du test, l'échec et actuellement en cours d'exécution.
Amélioration de la qualité du code grâce à la révision du code
Une exigence de collaboration et de longévité des logiciels scientifiques est une base de code lisible, maintenable et extensible comme base pour de nouveaux développements scientifiques. En réalité, cependant, tout le monde écrit le code différemment. Pour créer un niveau de base de lisibilité du code, limiter la casse du code et faciliter le débogage et l'extension du code, nous nous sommes mis d'accord sur un ensemble d'environ 200 conventions de codage, auxquelles tout le monde dans la communauté devrait adhérer. Bien qu'il soit difficile d'appliquer strictement toutes les conventions, certaines sont appliquées par des tests de qualité de code automatisés, un script d'embellissement personnalisé qui formate le code selon nos conventions et un système de modélisation de code basé sur Python pour divers types de classes courants.
Plusieurs outils et cadres de développement logiciel nous ont fourni des fonctionnalités qui ont façonné nos pratiques de développement logiciel. Nous avons intégré les fonctionnalités de Git et GitHub dans notre cadre de test, y compris la ramification, les demandes d'extraction et les révisions de code. Une demande d'extraction est une demande d'un développeur de fusionner le nouveau code d'une branche dans le référentiel principal. Le demandeur peut étiqueter des personnes spécifiques pour effectuer une révision ou diffuser un appel général à des réviseurs. Sur la base des commentaires reçus, il peut y avoir plusieurs séries de révisions. Lorsque tous les réviseurs approuvent la fusion, un ensemble final de tests est exécuté et le code est fusionné. Ce flux de travail est similaire aux pratiques de l'industrie du génie logiciel et améliore la qualité des contributions de code tout en abaissant la barrière psychologique pour que les nouveaux développeurs contribuent à la base de code sans craindre de la casser.
Interfaces avec la base de code principale
Pour faciliter la participation de divers nouveaux contributeurs, les méthodes peuvent être écrites en C ++, PyRosetta ou RosettaScripts. Le choix de l'interface se fait souvent en tenant compte des détails techniques de la nouvelle méthode ainsi que du niveau d'expérience et de confort du développeur. Les protocoles dans RosettaScripts ou PyRosetta (pour lesquels l'implémentation C ++ est le fondement commun) peuvent être développés plus rapidement et nécessitent moins de connaissances techniques, mais sont sujets à des modifications d'API et ne sont souvent pas fusionnés dans la base de code principale.
La première interface, la plus simple et la plus utilisée de la base de code est la ligne de commande. D'autres interfaces ont été mises en œuvre au fil des ans à différentes fins et pour faciliter le développement de protocoles personnalisés.
Par exemple, en 2008, le jeu vidéo Foldit a été publié, qui utilise Rosetta comme base et utilise une interface utilisateur graphique pour permettre au joueur de manipuler une structure protéique. Les principaux concepts scientifiques ont été adaptés avec une terminologie simplifiée pour rendre Foldit accessible à un public plus large. Par exemple, les contraintes sont appelées «élastiques», «shake» est utilisé pour l'optimisation et la conception du rotamère et «wiggle» pour un raffinement haute résolution. Le but du jeu est d'atteindre des scores élevés plutôt que de faibles énergies. Foldit est largement utilisé par le grand public pour résoudre de véritables énigmes scientifiques, comme outil d'enseignement pour les niveaux d'éducation de la maternelle à la 12e année, et par les laboratoires universitaires pour obtenir des informations et inspirer de nouvelles découvertes scientifiques.
En 2011, Fleishman a introduit RosettaScripts, qui est une interface basée sur XML qui permet le développement de protocoles personnalisés en recombinant et en configurant des objets existants. Il tire parti du cadre orienté objet de Rosetta3 et permet à l'utilisateur de créer une nouvelle recette sans écrire ni compiler de code C ++. Une connaissance approfondie de la base de code C ++ n'est pas requise, car la grande majorité des objets utilisés dans RosettaScripts sont documentés en ligne. L'utilisation de RosettaScripts a été facilitée par le cadre de définition de schéma XML (XSD) qui identifie les erreurs dans les scripts XML au moment de l'exécution, fournit des messages d'erreur détaillés et est désormais intégré dans notre documentation accessible aux utilisateurs.
Bien que RosettaScripts soit utile pour le développement de protocoles, il manque généralement un contrôle de flux et un contrôle détaillé de la façon dont les objets peuvent être manipulés. Si ceux-ci sont nécessaires et qu'un contrôle plus spécifique de certains objets est requis pour le développement, PyRosetta est l'outil de choix.
Depuis le début des années 2000, le langage Python est devenu le langage de programmation dominant dans de nombreuses disciplines scientifiques, dont la biologie et la chimie; en grande partie parce qu'il est facile à apprendre, renonce à la compilation de code et propose une gestion automatique de la mémoire et des packages, tout en fonctionnant mieux que de nombreux autres langages de script.
Après le travail initial de William Sheffler, en 2009, le groupe de Jeffrey Gray à l'Université Johns Hopkins a sorti PyRosetta, qui permet à l'utilisateur d'interagir avec presque toutes les structures de données sous-jacentes via des liaisons Python.
PyRosetta est destiné aux utilisateurs avancés et aux développeurs débutants car il nécessite une connaissance des bibliothèques Rosetta. Un cours d'études supérieures sur la modélisation de la structure des protéines avec PyRosetta est enseigné par Jeffrey Gray. Des ateliers mis à jour sont disponibles sur le site Web et un livre les décrivant a été publié en 2009.
Aspects sociaux
La communauté de développeurs RosettaCommons - une collaboration enrichissante
Les considérations techniques décrites ci-dessus reflètent des années de travail et d'itération par de nombreux développeurs scientifiques. Comme dans de nombreuses communautés de logiciels scientifiques, le nombre d'informaticiens et d'ingénieurs en logiciels dans notre communauté est faible par rapport au nombre de scientifiques ayant une expertise dans le domaine qui ont acquis des compétences en programmation sans formation formelle. Les développeurs vont au-delà de l'application du code existant aux problèmes actuels en ce qu'ils développent également de nouvelles méthodes pour répondre à de nouvelles questions scientifiques. En s'appuyant sur plus de 60 laboratoires dans le monde, la communauté comprend des développeurs ayant des antécédents en biochimie, chimie, physique, biologie, informatique, mathématiques, ingénierie, pharmacologie, physiologie moléculaire et autres disciplines connexes au premier cycle, aux cycles supérieurs, aux postdoctorants et aux professionnels. niveaux (chercheurs, chercheurs principaux) et leurs collaborateurs. Pour combler ces lacunes dans l'expertise (inévitables en raison de la grande portée du code) et travailler efficacement ensemble, nous favorisons une culture qui encourage la communication, la formation, le leadership et la sensibilisation.
Atteindre une base de code robuste avec des résultats scientifiques nécessite une collaboration
Les informaticiens et les ingénieurs logiciels (en particulier dans les environnements commerciaux) mettent souvent l'accent sur l'exactitude, la conception du code, la maintenance, la lisibilité et les performances. En revanche, les scientifiques universitaires favorisent souvent le développement rapide d'un code «salissant» pour tester une hypothèse, et les scientifiques sans formation informatique formelle mettent l'accent sur l'exactitude scientifique et apprennent les concepts du génie logiciel plus tard ou jamais. Ces facteurs conduisent à une base de code difficile à lire, à étendre, à maintenir et à tester, et qui fonctionne souvent mal. Dans notre communauté, nous encourageons, inspirons et enseignons activement ces concepts pour construire une culture qui apprécie et participe activement à la maintenance du code. Pour combattre ces barrières, le développement durable de logiciels nécessite
(1) une maintenance périodique du code
(2) une culture d'appréciation des concepts d'ingénierie logicielle. Nous renforçons une telle culture en distribuant un rapport annuelRosetta Service Award , qui, au cours des dix dernières années, a honoré les contributions du refactoring du code, du leadership du hackathon, des efforts de diversité et d'inclusion, etc. Ancrer ces valeurs dans notre communauté nous permet d'économiser beaucoup de temps, d'efforts et d'argent tout en interagissant étroitement avec les membres de la communauté nous permet de mettre en œuvre de nouvelles idées plus rapidement.
Communication
Comme notre logiciel est développé par de nombreux laboratoires dans le monde, une communication constante et efficace est cruciale. Plusieurs listes de diffusion sont en place pour les développeurs C ++ et PyRosetta, les PI, les journaux du serveur de test pour recevoir des mises à jour sur la rupture de code, le comité de diversité et une liste de tâches, entre autres. Nous avons également un espace de travail Slack pour une communication plus interactive et pour un support rapide au sein de notre communauté.
Nous avons en outre un MediaWiki depuis le début des années 2000 pour communiquer des annonces de conférences et de téléconférences.
La plupart de la documentation est passée à un wiki Gollum.
Les utilisateurs peuvent également poser des questions sur un forum consultable.
Les TeleCons mensuelles permettent aux développeurs, aux PI et au comité diversité de communiquer.
La variété des canaux de communication sert différents objectifs et crée un sentiment de communauté.
Interaction communautaire dans les réunions et les hackathons
L'esprit de collaboration étroite de RosettaCommons est encouragé par des réunions régulières, dont la plus importante est la RosettaCon annuelle de l'été. La réunion inaugurale de 2003 était semblable à une retraite de laboratoire, passant quelques jours dans les Cascades du Nord pour partager de nouveaux développements. Le dernier jour de la réunion est traditionnellement réservé aux activités de loisirs comme une occasion de faire connaissance avec les membres de la communauté. Parler de la science dans un cadre plus détendu a été une aubaine pour notre esprit communautaire. Pour beaucoup de gens, RosettaCon ressemble plus à des amis qui résolvent ensemble des problèmes scientifiques et techniques qu'à une conférence scientifique traditionnelle.
Summer RosettaCon a connu une croissance significative pour atteindre 270 personnes en 2017. Au fur et à mesure que l'audience augmentait, la conférence est passée d'une discussion principalement logicielle à des développements scientifiques. Tous les participants présentent leurs recherches dans une session d'affiches ou discutent. La qualité des pourparlers a considérablement augmenté, passant de pourparlers moins formels (similaires aux réunions de groupe) à des présentations bien conçues auxquelles on pourrait s'attendre lors de conférences scientifiques internationales. Les conférenciers couvrent tous les niveaux de carrière.

Figure 5 : Réunions.
Les développeurs se rencontrent lors de notre conférence annuelle d'été (RosettaCon). Les photos de notre deuxième RosettaCon en 2004 (à gauche) et de la conférence en 2017 (à droite) reflètent la croissance drastique de la communauté et l'augmentation de la diversité.
La communauté organise en outre des hackathons à la demande ( XRWs - eX treme Rosetta Workshops ) pour la maintenance et l'amélioration de la base de code. Dans ces XRW , une dizaine de personnes de différents groupes de recherche se réunissent en un seul endroit pour atteindre un objectif précis et bien défini.
Les XRW précédents se concentraient sur l'amélioration du temps de compilation et de l'utilisation de la mémoire en divisant les bibliothèques principales (2010) et les bibliothèques de protocoles (2011); l'amélioration de la fonction de partition (réunion de Talaris 2013); amélioration de la documentation, des captures de protocole et des didacticiels (2015 et 2016); généraliser le stockage des informations chimiques et la gestion des formats de fichiers moléculaires courants (2016); l'amélioration de la gestion de l'entrée RosettaScripts (2016); et généraliser les interfaces pour manipuler les acides aminés non canoniques, les glucides, les acides nucléiques et les sites de liaison aux métaux (2017).
Les XRW ont eu un impact énorme sur la maintenabilité, l'extensibilité et la convivialité de notre base de code tout en renforçant davantage l'esprit communautaire entre les participants.

Figure 6 : Hackathons.
L'organisation de hackathons réguliers peut considérablement améliorer la maintenabilité du code, la généralisation, la documentation et l'interaction dans la communauté.
Nos ateliers eXtreme Rosetta (XRW) sont organisés chaque année et ont eu un impact positif considérable sur nos logiciels et notre communauté
Formation pour les utilisateurs et les développeurs
Rosetta est écrite dans le but de comprendre des systèmes moléculaires complexes à l'interface entre la chimie, la physique et la biologie. Étant donné que le logiciel a été principalement développé par des scientifiques plutôt que par des ingénieurs en logiciel, il a toujours été difficile à utiliser. La création de diverses interfaces utilisateur et développeur (ligne de commande, PyRosetta, RosettaScripts) est le résultat d'essais pour relever certains de ces défis. De plus, notre communauté a mis en place un certain nombre d'ateliers pour familiariser les novices à l'utilisation de la suite logicielle et de sa base de code le plus rapidement possible.
En 2013, nous avons commencé à offrir un cours Bootcamp d'une semaine (maintenant appelé Code School) pour de petits groupes d'étudiants diplômés et de post-doctorants intéressés dans les laboratoires RosettaCommons. Le cours couvre les subtilités de la programmation C ++ et l'architecture de nos bibliothèques de logiciels dans des conférences et des laboratoires en classe. Nous gardons un ratio élevé d'enseignants sur les étudiants (~ 1: 5) afin que plusieurs enseignants puissent répondre aux questions simultanément pendant les séances de laboratoire. Le cours visait à former des non-informaticiens à devenir des développeurs seniors et, espérons-le, à remédier à notre déséquilibre entre les sexes. Des vidéos des cours d'école de code sont disponibles sur la chaîne YouTube RosettaCommons. En 2019, nous avons ajouté un cours de l'école de code PyRosetta, qui a une barrière à l'entrée encore plus faible car Python est un langage plus facile à utiliser. Les écoles de code directement enseignées par des développeurs seniors ont considérablement amélioré la qualité, la cohérence, la lisibilité, la documentation et la compréhension du code. Ils ont encore amélioré l'interaction et la communication au sein de la communauté et aidé les nouveaux arrivants à se sentir acceptés.
Parce que l'acquisition de compétences en développement logiciel prend généralement plusieurs mois à plusieurs années de formation, certains membres se déplacent entre les laboratoires RosettaCommons tout au long de leur carrière pour appliquer leurs compétences à différents types de problèmes de conception et de modélisation macromoléculaire. Ces personnes, ayant souvent plus de 6 ans d'expérience et de mémoire institutionnelle, jouent un rôle crucial dans l'avancement et le soutien de la base de code, de notre communauté et de la formation des nouveaux arrivants. De plus, le RosettaCommons soutient deux professeurs de recherche (Andrew Leaver-Fay et Rocco Moretti) qui utilisent leur expertise pour répondre à des questions techniques difficiles et qui sont qualifiés pour prendre des décisions majeures sur la base de code, et un ingénieur expérimenté expérimenté (Sergey Lyskov) qui a créé et maintient l'infrastructure de test. Collectivement, les 15 à 20 développeurs seniors, répartis dans plusieurs laboratoires.
Diversité, inclusion et rayonnement
Pour créer et maintenir une solide communauté de collaborateurs, il faut encourager et recruter les meilleurs talents. À mesure que notre communauté grandissait, nous avons remarqué que notre équipe manquait de genre et de diversité raciale / ethnique et qu'il nous manquait une fraction importante du talent disponible. Nous croyons qu'une culture inclusive et une composition diversifiée sont des conditions préalables à la formation d'une communauté éthique et juste de scientifiques, nous nous sommes donc concentrés sur le recrutement et le développement des scientifiques que nous n'avions pas inclus auparavant.
En plus d'offrir des écoles de code, deux premières étapes importantes ont été l'instauration d'un code de conduite et la création d'un énoncé de diversité pour saisir nos valeurs et nos aspirations.
En tant qu'éléments pouvant donner lieu à une action, les membres de RosettaCommons ont participé à diverses activités de sensibilisation qui remplissent plusieurs rôles:
(1) éduquer le grand public à la science,
(2) susciter l'intérêt pour les STEM (science, technology, engineering, and mathematics = science, technologie, ingénierie et mathématiques) chez les élèves de la maternelle à la 12e année et au premier cycle,
(3) accroître la diversité et l'inclusivité dans les RosettaCommons,
(4) le crowdsourcing des découvertes scientifiques.
Nos efforts de recrutement comprennent la participation régulière à des conférences qui visent à mettre en évidence la diversité dans les domaines STEM tels que Grace Hopper Celebration of Women in Computing, Annual Biomedical Research Conference for Minority Students (ABRCMS), ACM Richard Tapia Celebration of Diversity in Computing, et Society for Advancement of Chicanos/Hispanics and Native Americans in Science (SACNAS).
Ces conférences renforcent directement notre climat et notre culture, puisque les scientifiques de Rosetta à statut individuel rencontrent en personne ceux qui partagent leur identité dans d'autres laboratoires RosettaCommons et au-delà, forgeant ainsi des liens et des réseaux qui perdurent au-delà de ces rencontres. Les possibilités de développement professionnel offertes lors de ces conférences permettent aux scientifiques des groupes minoritaires d'acquérir des compétences et d'éclairer les délégués des groupes majoritaires.
Pour les étudiants de premier cycle intéressés par une expérience de recherche dans un laboratoire RosettaCommons, nous avons créé un programme REU (Research Experience for Undergraduates = Expérience de recherche pour les étudiants de premier cycle) financé par la NSF (Fondation nationale pour la science), le Rosetta Summer Intern Program (Programme interne d'été de Rosetta). Notre programme commence par une école de code d'une semaine où les étudiants apprennent à utiliser le logiciel, à naviguer dans le code et les cadres de travail (frameworks) les plus importants. Après cette semaine, les étudiants sont en mesure d'élaborer des protocoles de base et d'atteindre des objectifs de recherche spécifiques au cours de leur stage de 8 semaines, dont ils présentent les résultats à RosettaCon.
Nos efforts ont considérablement accru le nombre de femmes dans un domaine dominé par les hommes. Près de 30% des participants à RosettaCon en 2017 se sont identifiés comme des femmes, contre moins de 15% la plupart des années avant 2012. Près de 8% des participants s'identifient comme noirs, hispaniques ou multiraciaux. Les données démographiques de nos principaux développeurs et PI sont beaucoup moins diversifiées, ce qui nous donne l'humilité et la reconnaissance que les efforts de diversité doivent être maintenus pendant de nombreuses années à venir. Nous continuerons notre travail pour faire en sorte que les RosettaCommons soient un environnement universellement accueillant et favorable.
Participation du public à la science
Au début des années 2000, lorsque la prédiction de la structure des protéines était beaucoup moins facile et que les ressources de calcul étaient limitées, nous avons créé un projet de calcul distribué appelé Rosetta@home, grâce auquel des volontaires peuvent faire don de cycles informatiques inactifs pour la prédiction de la structure des protéines, l'arrimage et la conception.
Rosetta@home a été initialement lancé en 2005 et fonctionne sur l'infrastructure ouverte de Berkeley pour l'informatique en réseau (BOINC). Rosetta@home affiche un écran de veille pendant l'exécution des calculs lorsque le bureau de l'ordinateur fixe ou portable de l'utilisateur est inactif.
En 2015, Rosetta@home a été porté sur le système d'exploitation Android pour fonctionner sur les téléphones portables et les appareils mobiles des volontaires pendant les périodes de recharge, lorsque l'unité centrale est généralement sous-utilisée, pour effectuer des tâches de prédiction de la structure biomoléculaire.
De même, Human Proteome Folding Project (projet de repliement du protéome humain) était un effort combiné entre deux laboratoires Rosetta, l'Institute for Systems Biology et IBM - World Community Grid . Il a été lancé en 2004 dans le but de prédire les structures protéiques dans le génome humain, s'étalant sur 9 ans. Son successeur, le Microbiome Immunity Project, a été lancé en 2017 dans le but de prédire les structures protéiques du microbiome intestinal humain.
Diffusion et interaction avec les utilisateurs
Packaging et plateformes
Les simulations Rosetta nécessitent généralement des ressources de calcul haute performance (HPC), qui sont souvent publiques ou universitaires. En réponse à l'hétérogénéité des ressources HPC disponibles, notre logiciel doit pouvoir être construit sur une large gamme d'environnements matériels et informatiques. Nous avons personnalisé le système de construction SCons pour permettre aux utilisateurs de spécifier des paramètres de compilation spécifiques au système et de sélectionner un mode de construction particulier (par exemple, une interface de transmission de messages (Mode MPI) pour les clusters qui le prennent en charge ou l'exigent). Des versions binaires précompilées pour les distributions Linux et Mac 64 bits sont disponibles avec des versions hebdomadaires du code source (depuis 2013). Des rejets plus importants et numérotés ont lieu une ou deux fois par an. La suite logicielle fonctionne sur les trois principaux systèmes d'exploitation (Linux, macOS et Windows via le sous-système Windows pour Linux) et les architectures matérielles actuellement utilisées (puces Intel / AMD x86-64, architecture IBM Power [par exemple, les superordinateurs Blue Gene], et ARM pour téléphones portables et tablettes Android [pour Rosetta@home]). Dans le passé, les architectures DEC Alpha, Cray et Intel Itanium étaient également prises en charge.
Serveurs Web
Un moyen de réaliser des simulations, comme décrit dans les manuscrits publiés, est d'utiliser des serveurs Web qui présentent un nombre limité de paramètres à l'utilisateur. Le serveur Robetta a été déployé en 2003 et est couramment utilisé par les scientifiques à l'intérieur et à l'extérieur de notre communauté pour la génération de fragments, l'analyse des domaines et la prédiction de structure, l'analyse d'alanine et l'analyse d'interface ADN. Des laboratoires individuels ont également créé des serveurs pour la conception, la modélisation et la conception de dorsales flexibles, l'amarrage de peptides flexible et l'identification de l'interface protéine-protéine.
En 2013, le framework (cadre de travail) du serveur ROSIE a été créé pour simplifier la configuration de nouveaux serveurs Web pour les applications Rosetta.
En 2019, ROSIE héberge 21 protocoles de modélisation, compte plus de 7 300 utilisateurs enregistrés et a exécuté plus de 75 000 travaux pour un total de près de 7,8 millions d'heures de processeur.
Licence et commercialisation
Lors du développement d'un logiciel, il est important de penser à l'octroi de licences pour répondre aux questions suivantes : (1) par qui et dans quelles circonstances le logiciel sera-t-il utilisé ?; (2) comment les contributions à la base de code seront-elles faites et de qui seront-elles acceptées ?; (3) des revenus seront-ils générés et, dans l'affirmative, comment et à quoi seront-ils dépensés ?; et, (4) le choix de la licence restreindra-t-il l'utilisation de bibliothèques de logiciels externes ?
Le logiciel Rosetta est publié sous un modèle de licence unique, lié à son histoire. Initialement, lorsque le logiciel a été développé uniquement par des étudiants et des post-doctorants dans le laboratoire de David Baker à l'Université de Washington, il était clair que le partage ouvert et la prévention des conflits de propriété permettaient des progrès scientifiques innovants et rapides. Comme ces stagiaires ont créé leurs propres groupes de recherche dans d'autres institutions, ils ont cherché un modèle de licence pour préserver l'esprit de collaboration et encourager le partage en supprimant les obstacles au développement inter-institutionnel, conduisant à la création des RosettaCommons. En rejoignant les RosettaCommons, les institutions membres acceptent de fournir des droits non exclusifs sur le droit d'auteur pour les contributions apportées à la base de code, et les développeurs signent un accord attribuant le droit d'auteur du code écrit par eux à leur institution. Le logiciel est distribué gratuitement aux universitaires, aux gouvernements, et d'autres institutions sans but lucratif. Les entités commerciales soutiennent le développement continu en payant des frais de licence raisonnables qui sont basés sur le nombre d'employés.
Les revenus provenant des licences commerciales, ainsi que du financement public ou privé, sont utilisés pour soutenir les réunions, la maintenance des logiciels, les activités de sensibilisation, les formations, les échanges de laboratoires et les hackathons, les mini-subventions et les récompenses de service pour inciter et récompenser le soutien de la communauté. Les PI RosettaCommons peuvent demander des mini-subventions, qui sont généralement accordées pour maintenir, améliorer, étendre et prendre en charge la base de code, par exemple pour les améliorations des fonctions énergétiques, la réécriture des principaux cadres, le développement des interfaces utilisateur et de la documentation, etc.
Documentation
Rosetta est un logiciel intrinsèquement complexe écrit pour et par des experts dans le domaine, ce qui peut entraîner une interface compliquée avec de nombreuses options. Pour s'assurer que les scientifiques peuvent utiliser le logiciel efficacement, nos développeurs ont mis l'accent sur une documentation robuste avec des exemples de workflows (flux de production) de cas d'utilisation réels appelés captures de protocole. Les captures de protocole obligent un développeur à considérer le point de vue des utilisateurs finaux qui peuvent avoir différents problèmes biologiques à résoudre, un état d'esprit scientifique différent et des compétences techniques différentes. Étant donné que les subventions à vocation scientifique (par exemple des agences gouvernementales) ne fournissent généralement pas de temps pour la maintenance du code et la rédaction de la documentation, les mini-subventions, les XRW et les bourses de formation ou de service aident à encourager et à reconnaître cet important travail.
Au fil des ans, notre communauté a utilisé plusieurs types de documentation. Pour aider les développeurs, les conventions de codage pour C ++ (et plus tard Python) incluent l'utilisation de documentation en code au niveau de l'API basée sur les commentaires ( Doxygen). La combinaison des conventions de codage avec l'exigence d'écrire de la documentation dans le code facilite la lecture et la compréhension du code écrit par quelqu'un d'autre. Nous avons récemment développé un système de modèle de code basé sur Python pour les classes fréquemment utilisées afin de continuer à améliorer la cohérence et les commentaires de code, tout en réduisant considérablement le temps de développement et de débogage. Bien que la documentation Doxygen en code soit utile pour les développeurs, elle est moins avantageuse pour les utilisateurs finaux car elle décrit les fonctions internes et non l'interface avec un composant exécutable ou RosettaScripts.
Défis restants
Bien que nous ayons résolu de nombreux problèmes au cours des 20 dernières années, il reste plusieurs problèmes en suspens en ce qui concerne les trois principaux domaines explorés dans ce document :
(1) Technique : La tension entre les meilleures pratiques en matière de développement de logiciels et le progrès scientifique rapide signifie que nous devons fournir continuellement des incitations pour prioriser la maintenance, l'utilisabilité et la reproductibilité. De plus, nous reconsidérons actuellement les abstractions de base et les structures de données sur lesquelles nous nous appuyons depuis plus de dix ans pour utiliser des architectures matérielles massivement parallèles (par exemple, les GPU).
(2) Social : L'énorme croissance de notre communauté contribue aux questions de l'adhésion à la communauté et au laboratoire, à l'efficacité de nos efforts en matière de diversité, d'équité et d'inclusivité, comment préserver la petite ambiance informelle à mesure que nous continuons à grandir, et comment attribuer de manière appropriée le crédit (c'est-à-dire la paternité) dans un environnement qui est si clairement un effort d'équipe.
(3) Diffusion : La diversité des applications, des workflows (flux de production) et des architectures informatiques rend difficile la tâche de garantir que les utilisateurs externes peuvent facilement intégrer Rosetta dans leurs workflows et fournir des ressources pour le calcul de backend (arrière plan) pour les serveurs Web, ciblant un éventail plus large de scientifiques.
Conclusions
Ici, nous utilisons le logiciel Rosetta comme exemple pour mettre en évidence les succès, les erreurs commises et les leçons apprises au cours des deux dernières décennies alors que nous développions un outil logiciel scientifique dans une communauté mondiale, diversifiée et distribuée. Notre logiciel a été créé principalement dans un environnement académique et est largement utilisé au-delà des laboratoires dans lesquels il a été créé. Nous démontrons la nécessité de maîtriser les aspects techniques du développement logiciel pour créer un package qui permet l'utilisation d'outils complexes pour être à la pointe de la recherche de calcul informatique en biologie structurelle.
Les raisons de la réussite dans notre communauté sont nombreuses et largement imbriquées. Tout d'abord, notre communauté a abaissé les barrières de la collaboration scientifique et a ainsi permis une science révolutionnaire et une mise en œuvre plus rapide des bonnes idées. Sur le plan technique, nous avons bénéficié des premières conventions de codage établies, du contrôle des versions sur GitHub et de tests de code approfondis grâce à un cadre de travail. Nous entretenons en outre des interactions étroites avec les utilisateurs à l'intérieur et à l'extérieur de notre communauté, qui nous permettent de penser en dehors de nos modèles établis. La compréhension des besoins des utilisateurs et de la manière dont nos outils sont réellement utilisés (plutôt que la manière dont nous pensons qu'ils sont utilisés) nous pousse à améliorer continuellement nos logiciels pour les appliquer à des questions scientifiques "du monde réel". Pour tirer le meilleur parti de notre large communauté de développeurs et pour soutenir au mieux les utilisateurs de notre communauté, nous avons créé une documentation facilement modifiable qui s'est avérée transformatrice en complétant la couverture de la documentation et en soutenant notre large base d'utilisateurs externes.Les raisons de la réussite dans notre communauté sont nombreuses et largement imbriquées. Tout d'abord, notre communauté a abaissé les barrières de la collaboration scientifique et a ainsi permis une science révolutionnaire et une mise en œuvre plus rapide des bonnes idées. Sur le plan technique, nous avons bénéficié des premières conventions de codage établies, du contrôle des versions sur GitHub et de tests de code approfondis grâce à un cadre de travail. Nous entretenons en outre des interactions étroites avec les utilisateurs à l'intérieur et à l'extérieur de notre communauté, qui nous permettent de penser en dehors de nos modèles établis. La compréhension des besoins des utilisateurs et de la manière dont nos outils sont réellement utilisés (plutôt que la manière dont nous pensons qu'ils sont utilisés) nous pousse à améliorer continuellement nos logiciels pour les appliquer à des questions scientifiques "du monde réel". Pour tirer le meilleur parti de notre large communauté de développeurs et pour soutenir au mieux les utilisateurs de notre communauté, nous avons créé une documentation facilement modifiable qui s'est avérée transformatrice en complétant la couverture de la documentation et en soutenant notre large base d'utilisateurs externes.
Plus important encore, les logiciels scientifiques ne peuvent être maintenus sans une communauté autour d'eux, et nous comptons beaucoup sur notre communauté pour la formation, la communication, les hackathons et le partage de l'expertise, qu'elle soit scientifique ou liée au génie logiciel. Avec RosettaCommons, nous avons créé une communauté ouverte de développeurs qui se nourrit de collaboration plutôt que de concurrence : notre objectif commun est de faire progresser la science. Nous n'avons pas peur de nous attaquer aux questions scientifiques les plus difficiles ; en fait, elles nous motivent. Notre communauté étant large et dotée d'une hiérarchie plate, les membres ont voix au chapitre, quel que soit leur niveau de carrière, et sont encouragés à apporter leur contribution. C'est pourquoi notre communauté a établi ses propres normes, auxquelles les membres se conforment. La formation d'une communauté aussi soudée et collaborative n'aurait pas été possible sans un modèle de licence solide, fruit de décisions précoces et réfléchies qui ont profité à notre logiciel et à notre communauté au fil du temps. L'accord signé par tous les membres institutionnels et les développeurs de RosettaCommons nous permet de partager et de développer du code indépendamment des institutions et la licence commerciale de Rosetta permet à l'industrie de soutenir indirectement la maintenance et le développement continu par le biais des droits de licence.
La science est de plus en plus pratiquée en équipe pour aborder des questions complexes avec des méthodes avancées et il est nécessaire de relever les défis de la réalisation des objectifs scientifiques en grands groupes. Les défis auxquels nous avons été confrontés sont remarquablement similaires à ceux relevés par le Comité de la National Academy sur la science d'équipe ; nous pensons que ces actions et leçons sont indépendantes de la discipline scientifique et donc transférables à d'autres communautés. Notre communauté diversifiée a prospéré en s'engageant dans nos objectifs communs et en croyant fermement qu'en fait, nous sommes meilleurs ensemble.
Publié le 4 mai 2020
traduction de : https://doi.org/10.1371/journal.pcbi.1007507
Il s'agit d'un article en libre accès, libre de tout droit d'auteur, et peut être librement reproduit, distribué, transmis, modifié, construit ou autrement utilisé par quiconque à des fins licites. Le travail est mis à disposition sous la dédicace du domaine public Creative Commons CC0.